QUE SON CÓDIGOS INFORMÁTICOS???
 Los códigos son la esencia del lenguaje que manejan las computadoras. Los diversos lenguajes informáticos están expresados con base en un código. Comprender un lenguaje de este tipo es labor de programadores e implica un nivel de abstracción importante. El código php, el ASCII y el html son ejemplos de códigos informáticos.
Los códigos son la esencia del lenguaje que manejan las computadoras. Los diversos lenguajes informáticos están expresados con base en un código. Comprender un lenguaje de este tipo es labor de programadores e implica un nivel de abstracción importante. El código php, el ASCII y el html son ejemplos de códigos informáticos.
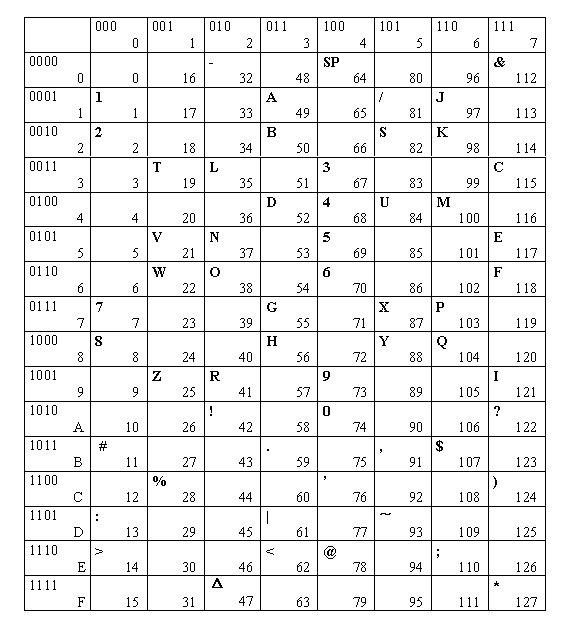
La mayoría de sistemas informáticos utilizan una misma codificación como base de algunas de sus aplicaciones y funciones. Al ser un código de caracteres con base en el alfabeto latino, el código ASCII es generalmente usado para representar textos, mediante las aplicaciones de procesador de textos que se basan también en esta codificación. ASCII comprende noventa y cinco caracteres y requiere 8 bits para formar cada uno de éstos. Es el sistema de símbolos y caracteres que utiliza la mayoría de computadoras.
Por su parte, el código html se refiere a un lenguaje generalmente utilizado para la elaboración de páginas web. Mediante html se describe y define la estructura y la forma del texto y de los contenidos de una página. html funciona por medio de etiquetas que, encerradas por símbolos como corchetes, representan cada uno de los atributos del texto y algunos de los comportamientos generados a los exploradores web.
Asimismo, El código php es empleado para la creación y el desarrollo de páginas web dinámicas, pudiendo ser insertado dentro de una construcción html. Se utiliza desde el servidor web, siendo el código php su lenguaje de entrada. No tiene dificultad ni con la mayoría de servidores web ni con los diversos sistemas operativos, constituyéndose así como uno de los más utilizados por los sitios web de todo el planeta.
Cada dígito decimal tiene una representación binaria codificada con 4 bits:
Decimal: 0 1 2 3 4 5 6 7 8 9
Códigos EBCDIC
EBCDIC (Extended Binary Coded Decimal Interchange Code) es un código estándar de 8 bits usado por computadoras mainframe IBM. IBM adaptó el EBCDIC del código de tarjetas perforadas en los años 1960 y lo promulgó como una táctica customer-control cambiando el código estándar ASCII.

Códigos ASCII

Por su parte, el código html se refiere a un lenguaje generalmente utilizado para la elaboración de páginas web. Mediante html se describe y define la estructura y la forma del texto y de los contenidos de una página. html funciona por medio de etiquetas que, encerradas por símbolos como corchetes, representan cada uno de los atributos del texto y algunos de los comportamientos generados a los exploradores web.
Asimismo, El código php es empleado para la creación y el desarrollo de páginas web dinámicas, pudiendo ser insertado dentro de una construcción html. Se utiliza desde el servidor web, siendo el código php su lenguaje de entrada. No tiene dificultad ni con la mayoría de servidores web ni con los diversos sistemas operativos, constituyéndose así como uno de los más utilizados por los sitios web de todo el planeta.
Códigos BCD
Binary-Coded Decimal (BCD) o Decimal codificado en binario es un estándar para representar números decimales en el sistema binario, en donde cada dígito decimal es codificado con una secuencia de 4 bits. Con esta codificación especial de los dígitos decimales en el sistema binario, se pueden realizar operaciones aritméticas como suma, resta, multiplicación y división de números en representación decimal, sin perder en los cálculos la precisión ni tener las inexactitudes en que normalmente se incurre con las conversiones de decimal a binario puro y de binario puro a decimal. La conversión de los números decimales a BCD y viceversa es muy sencilla, pero los cálculos en BCD se llevan más tiempo y son algo más complicados que con números binarios puros.
Cada dígito decimal tiene una representación binaria codificada con 4 bits:
Decimal: 0 1 2 3 4 5 6 7 8 9
BCD: 0000 0001 0010 0011 0100 0101 0110 0111 1000 1001
El código BCD (6-bit) ( Binary Coded Decimal) es un código estándar de 6 bits usado por ordenadoresmainframe : Borroughs, Bull, CDC, IBM, General Electric, NCR, Siemens, Sperry-Univac, etc ...
IBM creó un código para las tarjetas perforadas de los años 1960 que se extendió entre los otros fabricantes.
El código BCD (6-bit) fue la adaptación del código tarjeta perforada a código binario para poderlo cargar más fácilmente en la memoria del ordenador central.
El código BCD (6-bit) es pues un código binario que representa caracteres alfanuméricos y signos de puntuación. Cada carácter está compuesto por 6 bits (2 [[carácter]es octal), con estos 6 bits se pueden definir un total de 64 caracteres (2^6).
 |
EBCDIC (Extended Binary Coded Decimal Interchange Code) es un código estándar de 8 bits usado por computadoras mainframe IBM. IBM adaptó el EBCDIC del código de tarjetas perforadas en los años 1960 y lo promulgó como una táctica customer-control cambiando el código estándar ASCII.
EBCDIC es un código binario que representa caracteres alfanuméricos, controles y signos de puntuación. Cada carácter está compuesto por 8 bits = 1 byte, por eso EBCDIC define un total de 256 caracteres.
Existen muchas versiones ("codepages") de EBCDIC con caracteres diferentes, respectivamente sucesiones diferentes de los mismos caracteres. Por ejemplo al menos hay 9 versiones nacionales de EBCDIC con Latín 1 caracteres con sucesiones diferentes.
El siguiente es el código CCSID 500, una variante de EBCDIC. Los caracteres 0x00–0x3F y 0xFF son de control, 0x40 es un espacio, 0x41 es no-saltar página y 0xCA es un guion suave.
| Decimal | Hexadecimal | Character | Decimal | Hexadecimal | Character |
| 129 | 81 | a | 194 | C2 | B |
| 130 | 82 | b | 195 | C3 | C |
| 131 | 83 | c | 196 | C4 | D |
| 132 | 84 | d | 197 | C5 | E |
| 133 | 85 | e | 198 | C6 | F |
| 134 | 86 | f | 199 | C7 | G |
| 135 | 87 | g | 200 | C8 | H |
| 136 | 88 | h | 201 | C9 | I |
| 137 | 89 | i | 209 | D1 | J |
| 145 | 91 | j | 210 | D2 | K |
| 146 | 92 | k | 211 | D3 | L |
| 147 | 93 | l | 212 | D4 | M |
| 148 | 94 | m | 213 | D5 | N |
| 149 | 95 | n | 214 | D6 | O |
| 150 | 96 | o | 215 | D7 | P |
| 151 | 97 | p | 216 | D8 | Q |
| 152 | 98 | q | 217 | D9 | R |
| 153 | 99 | r | 226 | E2 | S |
| 162 | A2 | s | 227 | E3 | T |
| 163 | A3 | t | 228 | E4 | U |
| 164 | A4 | u | 229 | E5 | V |
| 165 | A5 | v | 230 | E6 | W |
| 166 | A6 | w | 231 | E7 | X |
| 167 | A7 | x | 232 | E8 | Y |
| 168 | A8 | y | 233 | E9 | Z |
| 169 | A9 | z | 64 | 40 | blank |
| 240 | F0 | 0 | 75 | 4B | . |
| 241 | F1 | 1 | 76 | 4C | < |
| 242 | F2 | 2 | 77 | 4D | ( |
| 243 | F3 | 3 | 78 | 4E | + |
| 244 | F4 | 4 | 79 | 4F | | |
| 245 | F5 | 5 | 80 | 50 | & |
| 246 | F6 | 6 | 90 | 5A | ! |
| 247 | F7 | 7 | 91 | 5B | $ |
| 248 | F8 | 8 | 92 | 5C | * |
| 249 | F9 | 9 | 93 | 5D | ) |
| 122 | 7A | : | 94 | 5E | ; |
| 123 | 7B | # | 96 | 60 | - |
| 124 | 7C | @ | 97 | 61 | / |
| 125 | 7D | ' | 107 | 6B | , |
| 126 | 7E | = | 108 | 6C | % |
| 127 | 7F | " | 109 | 6D | _ |
| 193 | C1 | A | 110 | 6E | > |
| 111 | 6F | ? |
Tiene como objetivo la representación de caracteres alfanuméricos. Es el utilizado por IBM para sus ordenadores de la serie IBM PC. En este sistema de caracteres, cada carácter tiene 8 bits, entonces, al tener 8 podremos representar hasta 2 elevado 8 = 256 caracteres. Sera posible almacenar letras mayúsculas , caracteres especiales etc… para los dispositivos de E/S.
Códigos FIELDATA
Es un código utilizado en transmisiones de datos de algunos sistemas militares y está orientado al lenguaje máquina.
Fieldata fue un proyecto pionero equipo dirigido por el Cuerpo de Señales del Ejército de los EE.UU. a finales de 1950 que pretende crear un único estándar para la recolección y distribución de información decampo de batalla. En este sentido se podría considerar como una generalización del sistema SAGE de la Fuerza Aérea de los EE.UU. que se está creando o menos al mismo tiempo.
A diferencia de SAGE, Fieldata estaba destinado a ser mucho más grande en su alcance, permitiendo que la información a ser obtenida de cualquier número de fuentes y formas. Gran parte del sistema Fieldataera las especificaciones para el formato de los datos tomarían, dando lugar a un conjunto de caracteresque sería una gran influencia en ASCII unos años más tarde. Fieldata también especifica los formatos de mensaje y hasta los estándares eléctricos para la conexión de máquinas Fieldata estándar juntos.
Otra parte del proyecto Fieldata fue el diseño y construcción de las computadoras en diferentes escalas,desde los terminales de entrada de datos en un extremo, a los centros de procesamiento de datos a nivelde teatro en el otro. Varios ordenadores Fieldata estándar se construyeron durante la vida del proyecto,incluyendo el MOBIDIC transportable de Sylvania y el BASICPAC y LOGICPAC de Philco. Otro sistema,ARTOC, tenía por objeto proporcionar una salida gráfica (en forma de diapositivas de fotografías), pero nunca se completó.
Debido Fieldata no especificó los códigos para la interconexión y control de la transmisión de datos, los diferentes sistemas utilizados diferentes funciones de control. Intercomunicación entre ellos era difícil (Mackenzie, 64).
Fieldata es el juego de caracteres original utilizado internamente en las computadoras UNIVAC de la serie1100, que representa la sexta parte de la palabra de 36 bits de ese equipo. El sucesor directo del UNIVAC1100 es las computadoras de la serie Unisys 2200, que utilizan Fieldata hasta nuestros días (aunqueASCII ahora también es común con cada carácter codificado en 1/4 de una palabra, o 9 bits). Debido a que algunos de los personajes Fieldata no están representados en ASCII, el Unisys 2200 utiliza "^" '"' y los caracteres '_' para los códigos 04, 076 y 077 (octal), respectivamente.
El proyecto Fieldata corrió desde 1956 hasta que fue detenido durante una reorganización en 1962.
A diferencia de SAGE, Fieldata estaba destinado a ser mucho más grande en su alcance, permitiendo que la información a ser obtenida de cualquier número de fuentes y formas. Gran parte del sistema Fieldataera las especificaciones para el formato de los datos tomarían, dando lugar a un conjunto de caracteresque sería una gran influencia en ASCII unos años más tarde. Fieldata también especifica los formatos de mensaje y hasta los estándares eléctricos para la conexión de máquinas Fieldata estándar juntos.
Otra parte del proyecto Fieldata fue el diseño y construcción de las computadoras en diferentes escalas,desde los terminales de entrada de datos en un extremo, a los centros de procesamiento de datos a nivelde teatro en el otro. Varios ordenadores Fieldata estándar se construyeron durante la vida del proyecto,incluyendo el MOBIDIC transportable de Sylvania y el BASICPAC y LOGICPAC de Philco. Otro sistema,ARTOC, tenía por objeto proporcionar una salida gráfica (en forma de diapositivas de fotografías), pero nunca se completó.
Debido Fieldata no especificó los códigos para la interconexión y control de la transmisión de datos, los diferentes sistemas utilizados diferentes funciones de control. Intercomunicación entre ellos era difícil (Mackenzie, 64).
Fieldata es el juego de caracteres original utilizado internamente en las computadoras UNIVAC de la serie1100, que representa la sexta parte de la palabra de 36 bits de ese equipo. El sucesor directo del UNIVAC1100 es las computadoras de la serie Unisys 2200, que utilizan Fieldata hasta nuestros días (aunqueASCII ahora también es común con cada carácter codificado en 1/4 de una palabra, o 9 bits). Debido a que algunos de los personajes Fieldata no están representados en ASCII, el Unisys 2200 utiliza "^" '"' y los caracteres '_' para los códigos 04, 076 y 077 (octal), respectivamente.
El proyecto Fieldata corrió desde 1956 hasta que fue detenido durante una reorganización en 1962.
Códigos ASCII
ASCII (acrónimo inglés de American Standard Code for Information Interchange — Código Estándar Estadounidense para el Intercambio de Información), pronunciado generalmente [áski] o [ásci] , es un código de carácteres basado en el alfabeto latino, tal como se usa en inglés moderno y en otras lenguas occidentales. Fue creado en 1963 por el Comité Estadounidense de Estándares (ASA, conocido desde 1969 como el Instituto Estadounidense de Estándares Nacionales, o ANSI) como una refundición o evolución de los conjuntos de códigos utilizados entonces en telegrafía. Más tarde, en 1967, se incluyeron las minúsculas, y se redefinieron algunos códigos de control para formar el código conocido como US-ASCII.
El código ASCII utiliza 7 bits para representar los carácteres, aunque inicialmente empleaba un bit adicional (bit de paridad) que se usaba para detectar errores en la transmisión. A menudo se llama incorrectamente ASCII a otros códigos de carácteres de 8 bits, como el estándar ISO-8859-1, que es una extensión que utiliza 8 bits para proporcionar carácteres adicionales usados en idiomas distintos al inglés, como el español.
ASCII fue publicado como estándar por primera vez en 1967 y fue actualizado por última vez en 1986. En la actualidad define códigos para 32 carácteres no imprimibles, de los cuales la mayoría son carácteres de control obsoletos que tienen efecto sobre cómo se procesa el texto, más otros 95 carácteres imprimibles que les siguen en la numeración (empezando por el carácter espacio).
Casi todos los sistemas informáticos actuales utilizan el código ASCII o una extensión compatible para representar textos y para el control de dispositivos que manejan texto como el teclado. No deben confundirse los códigos ALT+número de teclado con los códigos ASCII.
Es el recomendado por en ANSI (instituto estadounidense de normas). Utiliza grupos de 7 bits por carácter, permitiendo 2 elevado 7 = 128 caracteres diferentes, lo que es suficiente para el alfabeto con letras mayúsculas y minúsculas y símbolos de una maquina de escribir corriente. Un código ASCII extendido usa 8 bits por carácter, lo que añade otros 128 caracteres posibles. Este juego de códigos mas amplio permite que se agreguen los símbolos de lenguajes extranjeros y varios símbolos gráficos. ASCII es el código mas extendido y es utilizado por sistemas operativos como DOS, Windows, y UNIX.
 | ||||
Un ejemplo: todo lo que introducimos en nuestro PC, suponiendo que este bajo un plataforma antes mencionada, o por ejemplo GNU/Linux, seria en código ASCII, claro que eso al procesarlo al ordenador, se pasaría a binario en paquetes de 8 bits osease 1 byte de información por carácter.
Código GRAY
El código binario reflejado o código Gray, nombrado así en honor del investigador Frank Gray, es un sistema de numeración binario en el que dos valores sucesivos difieren solamente en uno de sus dígitos.
El código Gray fue diseñado originalmente para prevenir señales ilegales (señales falsas o viciadas en la representación) de los switches electromecánicos, y actualmente es usado para facilitar la corrección de errores en los sistemas de comunicaciones, tales como algunos sistemas de televisión por cable y la televisión digital terrestre.
No es ponderado ni es un código aritmético; esto es, no hay pesos específicos asignados a las posiciones de los bits. El carácter importante del código Gray es que exhibe solo un cambio de bit único de un numero de código al siguiente. Esta propiedad es muy importante para muchas aplicaciones, tales como codificadores de posizian axial, donde la susceptibilidad a errores se incrementa con el numero de cambios de bit entre números adyacentes en una secuencia.
La tabla siguiente es una lista del código Gray de cuatro bits para números decimales del 0 al 15. Los números binarios se muestran en la tabla como una referencia. Como los números binarios, el código Gray puede tener cualquier numero de bits. Note el cambio de bit único entre los números sucesivos del código Gray. Por ejemplo, dirigiéndose del decimal 3 al 4, el código Gray cambia de 0010 a 0110, mientras que el binario cambio de 0011 a 0100, un cambio de tres bits. El único cambio de bit se origina en el tercer bit de la derecha en el código Gray; los otros permanecen iguales.
Secuencia
|
Binario
|
Gray
|
Secuencia
|
Binario
|
Gray
| |
0
|
0000
|
0000
|
8
|
1000
|
1100
| |
1
|
0001
|
0001
|
9
|
1001
|
1101
| |
2
|
0010
|
0011
|
10
|
1010
|
1111
| |
3
|
0011
|
0010
|
11
|
1011
|
1110
| |
4
|
0100
|
0110
|
12
|
1100
|
1010
| |
5
|
0101
|
0111
|
13
|
1101
|
1011
| |
6
|
0110
|
0101
|
14
|
1110
|
1001
| |
7
|
0111
|
0100
|
15
|
111
|
Código JOHNSON
Se denomina código Johnson (Johnson-Mobius) al código binario continuo y cíclico (al igual que el código Gray) cuya capacidad de codificación viene dada por 2n, siendo n el número de bits. Para codificar los dígitos decimales se necesitarán por lo tanto 5 bits:
La secuencia es sencilla,consiste en desplazar todos los bits uno a la izquierda y en el bit menos significativo se coloca el complementario del que estaba mas a la izquierda.
Dada la simplicidad del diseño de contadores que lleven el cómputo en este código, se utiliza en el control de sistemas digitales sencillos de alta velocidad.
Proporciona una mayor protección contra errores aunque es menos eficiente en memoria que el código binario decimal.
No hay comentarios.:
Publicar un comentario